

Find More Than One Paragraph with GREP

GREP is, by default, set up to find text inside a paragraph. That is, if you search for .+ (one or more of any character), then it will find those characters from the beginning of the paragraph to the end of the paragraph, and then stop. That’s it. But what if you’re trying to match a pattern across multiple paragraphs?
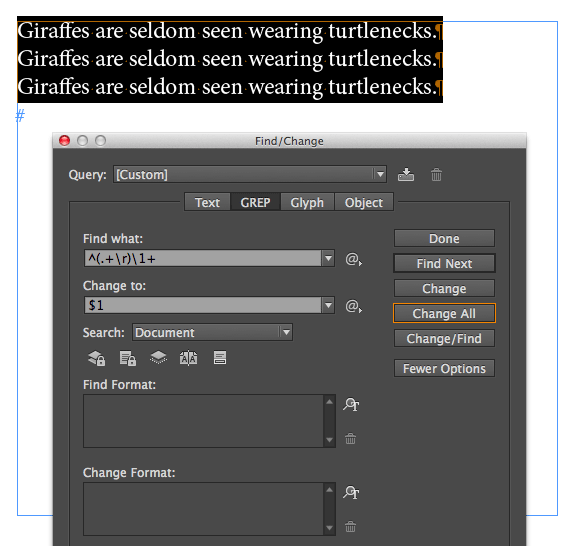
For example, what if you know you have three paragraphs in the middle of your story, and the first paragraph starts with “Giraffes” and the last paragraph ends with “fish.” You can do this with the code ^Giraffes(\r|.)+fish.$

The trick there is a simple one: the code inside the parentheses says find “any character or a return character.” (The caret means “beginning of paragraph,” the dollar sign means “end of paragraph,” and the vertical bar means “or”.)
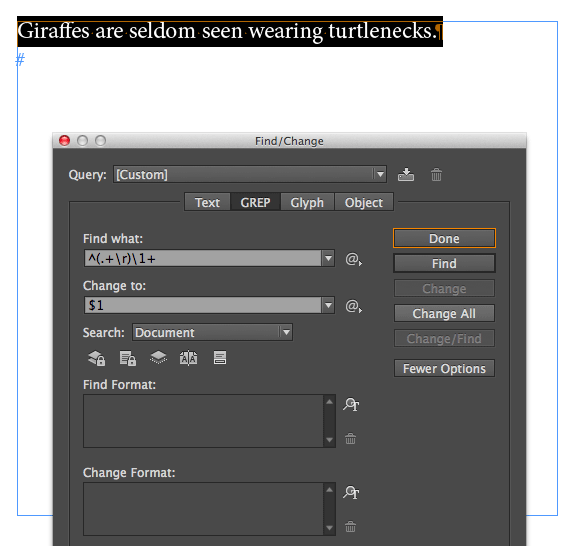
By specifically including the return character, we can find more than one paragraph. That’s why the code ^(.+\r)\1+ means “Find duplicate paragraphs/lines in a list.” In other words, “find everything in the paragraph–including the paragraph marker–followed by one or more exact duplicates of that.” If you want to remove the duplicate(s), then type $1 into the Replace With field.
Just remember that this code won’t work with GREP Styles, because those are specifically for applying formatting within a single paragraph!
Grep Goodies, Hummm! ;-)
You can also set the Modifiers > Single-Line On using (?s) to make an entire story behave like a single paragraph.
So this will give you this for your first exemple (?s)^Giraffes.+fish.$
I agree with you Jean, but that will consider the full story as one paragraph. What if? If you want to select the the central most or some other two paragraphs in a long story to apply some formatting or do some other stuff, then Modifiers will not work. Let’s say I want to select the two paragraphs at the beginning of the story to apply some formatting than I must say that \r will be the right choice.
I do remember a similar post, but never heard about the end result by the user:
https://creativepro.com/topic/paragraph-style-exception
Using the modifiers is not always the right choice… It’s just another option that could be use in some case. Peoples tend to forget about it.
I’m using CS6 and it doesn’t work for me. I have the following GREP that works.
([^\r]+(\r|$))+
What if instead of Giraffes and fish I want to find all paragraphs between hard type codes that use angle brackets and forward slashes? These are commonly used in editing manuscripts.
The 1st para I want to find starts with Open angle bracket + I + close angle bracket.
The last para ends with Open angle bracket + forwardslash + I + close angle bracket.
I’ve tried this Giraffes & fishes string with my bracketed codes but I don’t understand how to use escape characters here.
Amy, take a look at these articles:
https://creativepro.com/styling-code-snippets-grep-styles.php
https://creativepro.com/findbetween-a-useful-grep-string.php
https://creativepro.com/favorite-grep-expressions-you-can-use.php
i checked all those articles and still can’t figure out how to format several paragraphs at once without taking out the paragraph return :(
this my code right now but there are paragraph returns in between as well.
(?<=\[ing]).*?(?=\[//ing])
Seriously, GREP is like that cool-without-trying-to-be friend in high school — full of one-liners and answers to problems. It’s just so useful in so many ways. Thank you for posting this helpful query!
So, now that I have this super helpful query, I added it as the last line in my FindChangeByList text file (it includes quite a few other queries). But, when I run the FindChangeByList script in InDesign, it’s like this query is completely ignored (the other queries in the file work exactly as expected).
And yes, in the file I’m using to test with, the ^(.+\r)\1+ query does remove the duplicate paragraphs, as expected. Any ideas why the FindChangeByList wouldn’t recognize it?
This is what it looks like in the text file for my FindChangeByList script:
grep {findWhat:”^(.+\r)\1+”} {changeTo:”$1″}
Thanks for your help!
Rhea: Well, the good news is that I can recreate your problem. The bad news is that it is quite mysterious and I cannot figure out why it doesn’t work. My guess is that it’s a bug in the script.
If you have to do a lot of these kinds of find/changes, I would recommend looking at Multi Find/Change by Automatication.com. I bet it would do this properly.
Rhea…
Try this line:
grep {findWhat:”^(.+\\r)\\1+”} {changeTo:”$1″}
In Javascript you need to add a \ before every \ in the query.
Wow, you two are speedy! Jean-Claude, I was just adding a follow up, with the same results about adding two backslashes. Thank you both!
This is the first time I’ve heard of adding two backslashes because of javascript — does that second backslash cause any (unforseen) problems in other queries or is that a solution across the board? (i know this is mostly unrelated to the original post, so forgive me for going off-topic). In an adobe forum response that I read, it sounded like they didn’t really recommend adding two slashes… https://forums.adobe.com/thread/889708
again, thank you both for the help!
HI, I’M DESPERATE :) I can’t fin a way to detect duplicate blocks of text like in a whole document.
Like page 3 :
block of text : {
Paragraph of text 1.
Paragraph of text 2. }
And page 27 :
Block of text : {
Paragraph of text 1.
Paragraph of text 2. } = this block is a duplicate of the one in page 3
Thank you for your help !
Olivier: That is a fascinating question. I have never seen a “find duplicate paragraphs anywhere in my story” or “find duplicate phrases in my document” kind of tool. Perhaps it could be done with a script…?
I went searching and found this post about how to do something similar in MS Word: https://www.techandlife.com/2012/06/finding-duplicate-paragraphs-in-microsoft-word/
Any idea how to remove the duplicates but keep the returns? So you end up with this:
Giraffes are seldom seen wearing turtlenecks.
\r
\r
\r
Basically, I’m trying to delete duplicates in a table column by pulling them out, converting to text, removing duplicates but keeping the returns, then refilling the column.
John,
You can run this query repeatedly until there is no more duplicates.(CS6 and above)
F: ^(.+\r)\r*\K\1
C: \r
Doesn’t seem to do anything different than the original. Thanks though.
Seems to pick up every other one and replace, but in the case of 3 or more, I’m still left with duplicates now separated by returns. I’m wondering there’s a way to work back from instances, like 10 in a row, then 9 in a row, etc.
Run it more than one time, until there is no more match.
How do I detect duplicates in pharagraph that have sentences in multiple lines for example:
Addddddjdjdjjdjdndjdjidjdjdjdkdk?
kdjdjdjdjdjdjdjddkd.
sksksksksksksksls.
kdkdkdkd kdkdkdkd.
I want to find duplicates within a text document that match all the sentences of the above group and not just one line.hope I am clear.